As an example, big data in medical care is ending up being increasingly essential-- early discovery of illness, exploration of new medications, and also customized therapy prepare for patients are all examples of big data applications in medical care. Tidy data, or data that relates to the client and arranged in a way that enables significant analysis, calls for a great deal of job. Data scientists invest 50 to 80 percent of their time curating and preparing information prior to it can actually be used. Although new modern technologies have been established for information storage, information quantities are increasing in size regarding every two years. Organizations still battle to equal their data and also locate ways to efficiently save it Although the idea of big information itself is reasonably new, the beginnings of big information sets go back to the 1960s and '70s when the world of information was just getting going with the very first data facilities and the growth of the relational data source.
What are the 3 kinds of large information?
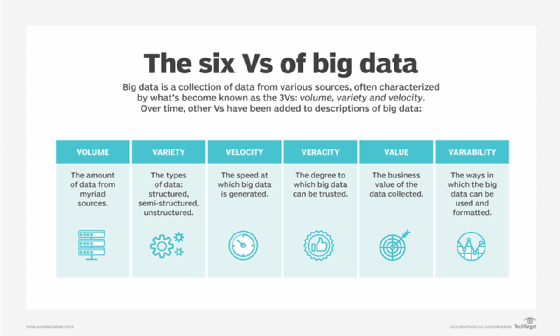
The category of big information is divided into three components, such as Structured Information, Unstructured Information, and Semi-Structured Information.
Its adaptable schema accepts information in any kind and quantity-- so you don't have to stress over storage space as the quantity of data increases. This makes it possible for companies to make data-driven decisions to develop smart companies. Big information is the key to building an affordable, extremely performant setting which can profit services and clients alike.
Big Data Utilize Cases
It is likewise highly reputable, with solid support for distributed systems as well as the capacity to manage failings without shedding data. In this way, the details coming from the raw data is readily available practically quickly. There are various applications where real-time processing is important-- streaming information, radar systems, and also client service systems, simply to name a few. Typical data tools work best when they have the information in the very same style and also kind, with other types that do not fit the framework being omitted. Nevertheless, it's difficult to fit every one of that disorganized information into the requirements, making common information devices hardly useful now. As we saw previously, MongoDB has a document-based structure, which is a much more all-natural way to keep disorganized information.
- Unstructured information comes from details that is not organized or easily translated by typical data sources or information models, as well as usually, it's text-heavy.
- Big information can assist you address a variety of business tasks, from client experience to analytics.
- It appears to me that the interpretation of the huge data provides big firms access to their very own speedy Boyd loopholes http://spenceranea813.bearsfanteamshop.com/large-information-trends-that-are-readied-to-form-the-future in a manners they will not formerly have expected.
- Yet real inspiration-- why business spends so heavily in all of this-- is not information collection.
- This made it feasible to estimate the store's sales on that particular vital day even prior to Macy's itself had videotaped those sales.
At the exact same time, the progressively decreasing prices of all the elements of computer-- storage space, memory, processing, transmission capacity, and so on-- suggest that formerly pricey data-intensive approaches are swiftly ending up being affordable. Multidimensional big data can additionally be stood for as OLAP information cubes or, mathematically, tensors. Variety database systems have actually set out to supply storage and also top-level question assistance on this data kind.
Getting Started With Big Data Analytics
Another Apache open-source huge data technology, Flink, is a distributed stream processing structure that enables the exam as well as processing of streams of data in genuine time as they stream into the system. Flink is made to be highly reliable and able to process large volumes of information swiftly, making it particularly fit for handling streams of information which contain numerous events taking place in actual time. Besides devoted storage solutions for businesses that can be included essentially unlimited ability, large data frameworks are typically horizontally scaled, implying that extra processing power can be conveniently added by adding a lot more machines to the cluster. This enables them to handle huge volumes of data and to scale up as required to fulfill the needs of the workload. Furthermore, numerous big data structures are created to be distributed and parallel, implying that they can process data across multiple makers in parallel, which can significantly enhance the rate and also effectiveness of information processing. Typical strategies to keeping information in relational databases, information silos, and information centers are no longer adequate as a result of the dimension and variety these Visit this link days's data.
Beyond the 'big red blob': UBS sees future in data mesh for analytics - www.waterstechnology.com
Beyond the 'big red blob': UBS sees Additional hints future in data mesh for analytics.

Posted: Thu, 09 Jun 2022 07:00:00 GMT [source]